4.4 In-Class Exercises
In these exercises, we will continue with our re-analysis/replication of the Kestilä (2006) results. Rather than attempting a direct replication, we will now redo the analysis using exploratory factor analysis (EFA).
4.4.1
Load the ess_round1.rds dataset.
- These are the data that we saved after the data processing in the At-Home Exercises.
4.4.2
Kestilä (2006) claimed that running a PCA is a good way to test if the questions in the ESS measure attitudes towards immigration and trust in politics.
- Based on what you’ve learned from the readings and lectures, do you agree with this position?
Click for explanation
Hopefully not. PCA is not a method for estimating latent measurement structure; PCA is a dimension reduction technique that tries to summarize a set of data with a smaller set of component scores. If we really want to estimate the factor structure underlying a set of observed variables, we should use EFA.
4.4.3
Suppose you had to construct the trust in politics and attitude towards immigration scales described by Kestilä (2006) based on the theory and background information presented in that article.
- What type of analysis would you choose?
- What key factors would influence your decision?
Click for explanation
- We are trying to estimate meaningful latent factors, so EFA would be an appropriate method.
- The theory presented by Kestilä (2006) did not hypothesize a particular number
of factors, so we would need to use appropriate techniques to estimate the best
number. In particular, combining information from:
- Scree plots
- Parallel analysis
- Substantive interpretability of the (rotated) factor loadings
- Since the factors are almost certainly correlated, we should apply an oblique rotation.
We will now rerun the two PCAs that you conducted for the
At-Home Exercises using EFA. We will estimate the
EFA models using the psych::fa() function, but we need to know how many
factors to extract.
- We could simply estimate a range of solutions and compare the results.
- We can restrict the range of plausible solutions and save some time by first checking/plotting the eigenvalues and running parallel analysis.
4.4.4
Estimate the number of latent factors underlying the Trust items based on the eigenvalues, the scree plot, and parallel analysis.
- How many factors are suggested by each method?
1. Eigenvalue estimation
Click to show code
## Load the psych package:
library(psych)
## Run a trivial EFA on the 'trust' items
efa_trust0 <- select(ess, trstlgl:trstplt) %>%
fa(nfactors = 1, rotate = "none") Click for explanation (EFA)
First, we run a trivial EFA using the psych::fa() function to estimate the
eigenvalues.
We don’t care about the factors yet, so we can extract a single factor.
We also don’t care about interpretable solutions, so we don’t need rotation.
## [1] 4.980 0.716 0.482 0.165 0.069 0.014 -0.066 -0.092 -0.182 -0.207
## [11] -0.284 -0.296 -0.319Click for explanation (eigenvalue extraction)
We can check the eigenvalues to see what proportion of the observed variance is accounted for by each additional factor we may extract.
Since only one eigenvalue is greater than one, the so-called “Kaiser Criterion” would suggest extracting a single factor.
- The Kaiser Criterion is not a valid way to select the number of factors in EFA. So, we don’t want to rely on this information alone.
We can still use the eigenvalues to help us with factor enumeration, though. One way to do so is by plotting the eigenvalues in a scree plot.
2. Scree plot
Click to show code
Given a vector of estimated eigenvalues, we can create a scree plot using
ggplot() and the geom_line() or geom_path() geometry.
library(ggplot2)
library(magrittr)
efa_trust0 %$% data.frame(y = values, x = 1:length(values)) %>%
ggplot(aes(x, y)) +
geom_line() +
xlab("No. of Factors") +
ylab("Eigenvalues")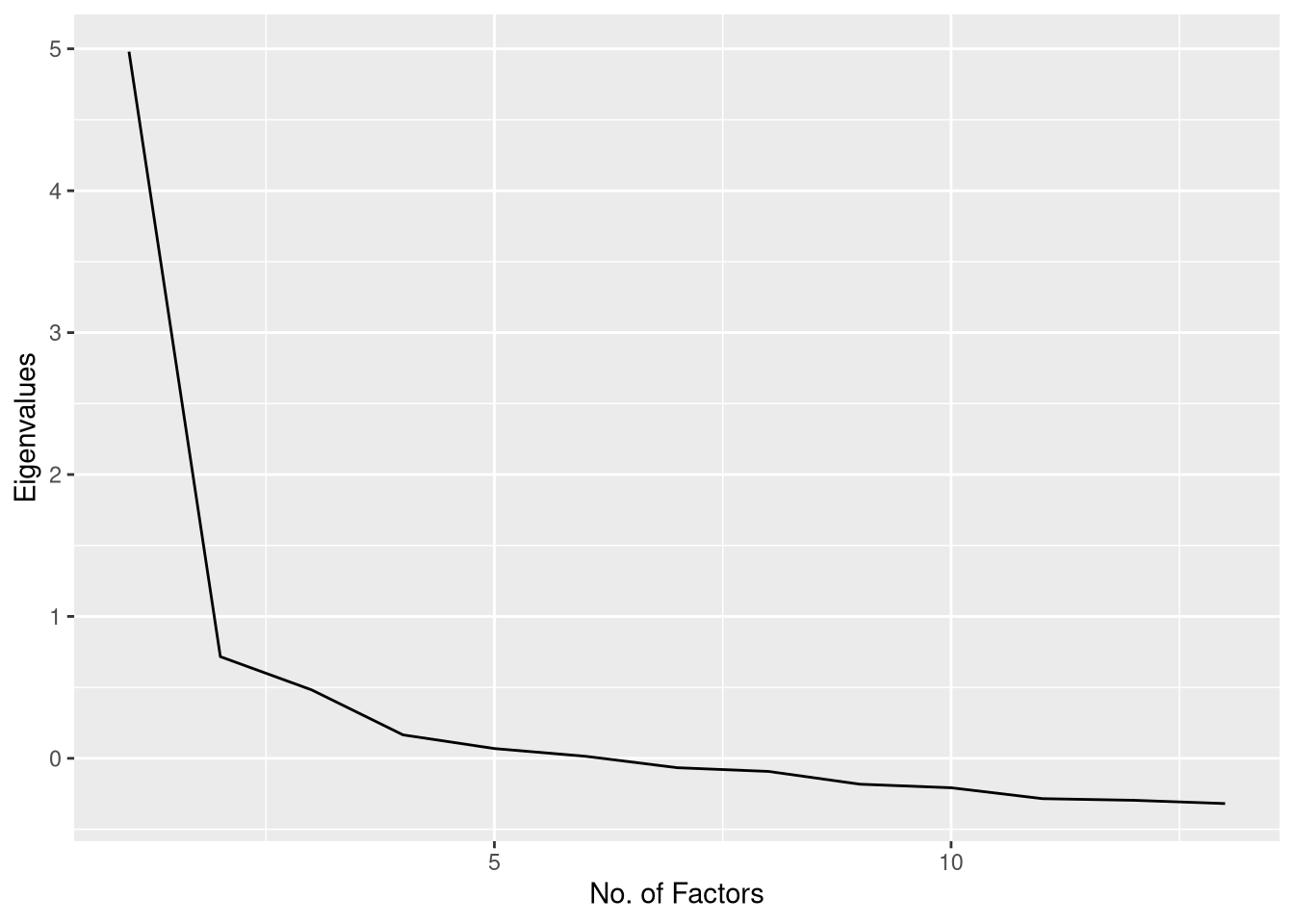
We can also use the psych::scree() function to create a scree plot directly
from the data.
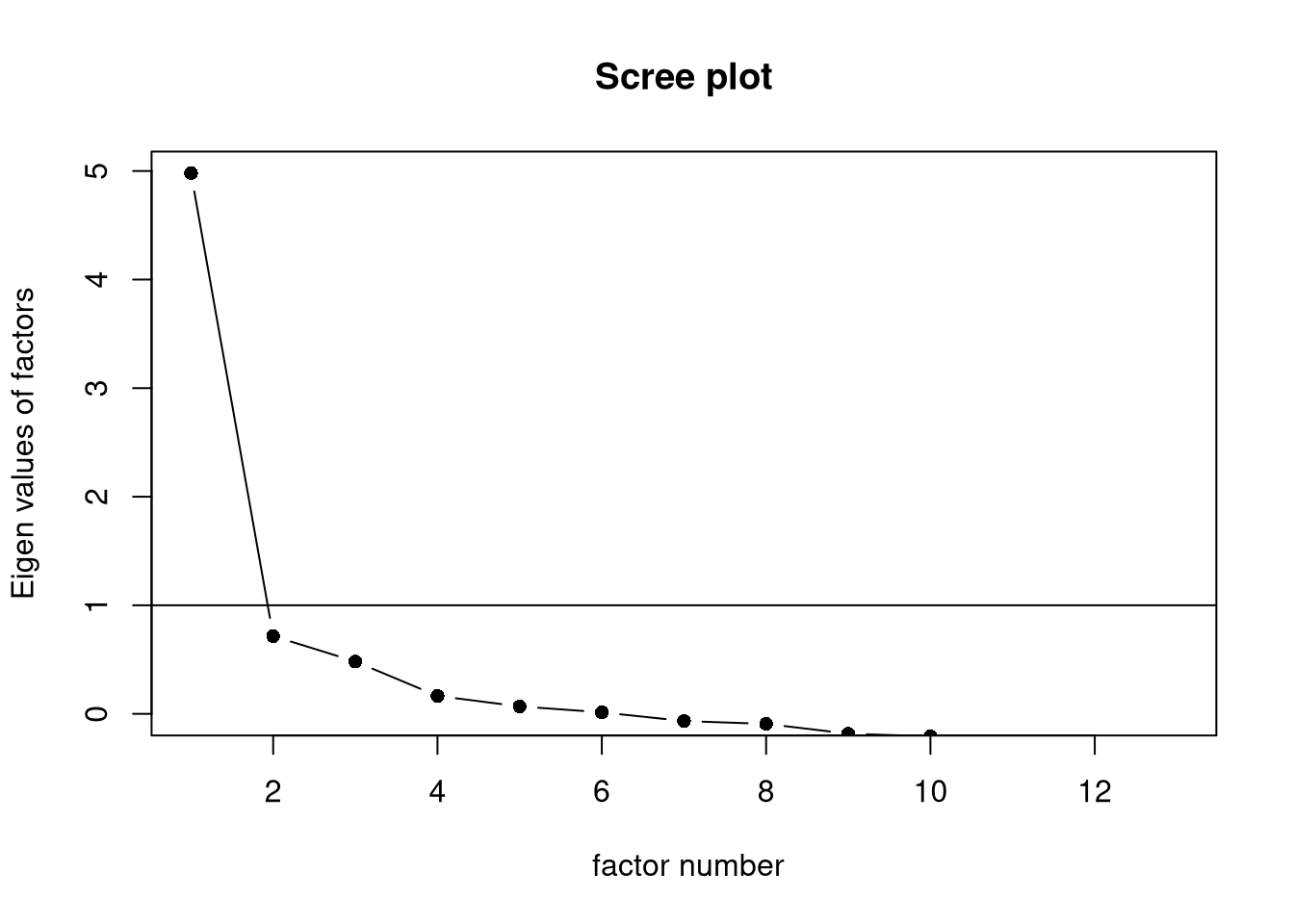
Click for explanation (scree plot)
Although the scree plot provides useful information, we need to interpret that information subjectively, and the conclusions are sometimes ambiguous, in this case.
- In this case, the plot seems to suggest either one or three components, depending on where we consider the “elbow” to lie.
As recommended in the lecture, we can also use “parallel analysis”
(Horn, 1965) to provide more objective
information about the number of factors. We’ll use the psych::fa.parallel()
function to implement parallel analysis.
Parallel analysis relies on randomly simulated/permuted data, so we should set a seed to make sure our results are reproducible.
We can set the
fa = "fa"option to get only the results for EFA.
3. Parallel Analysis
Click to show code
## Set the random number seed:
set.seed(235711)
## Run the parallel analysis:
pa_trust <- select(ess, trstlgl:trstplt) %>%
fa.parallel(fa = "fa") 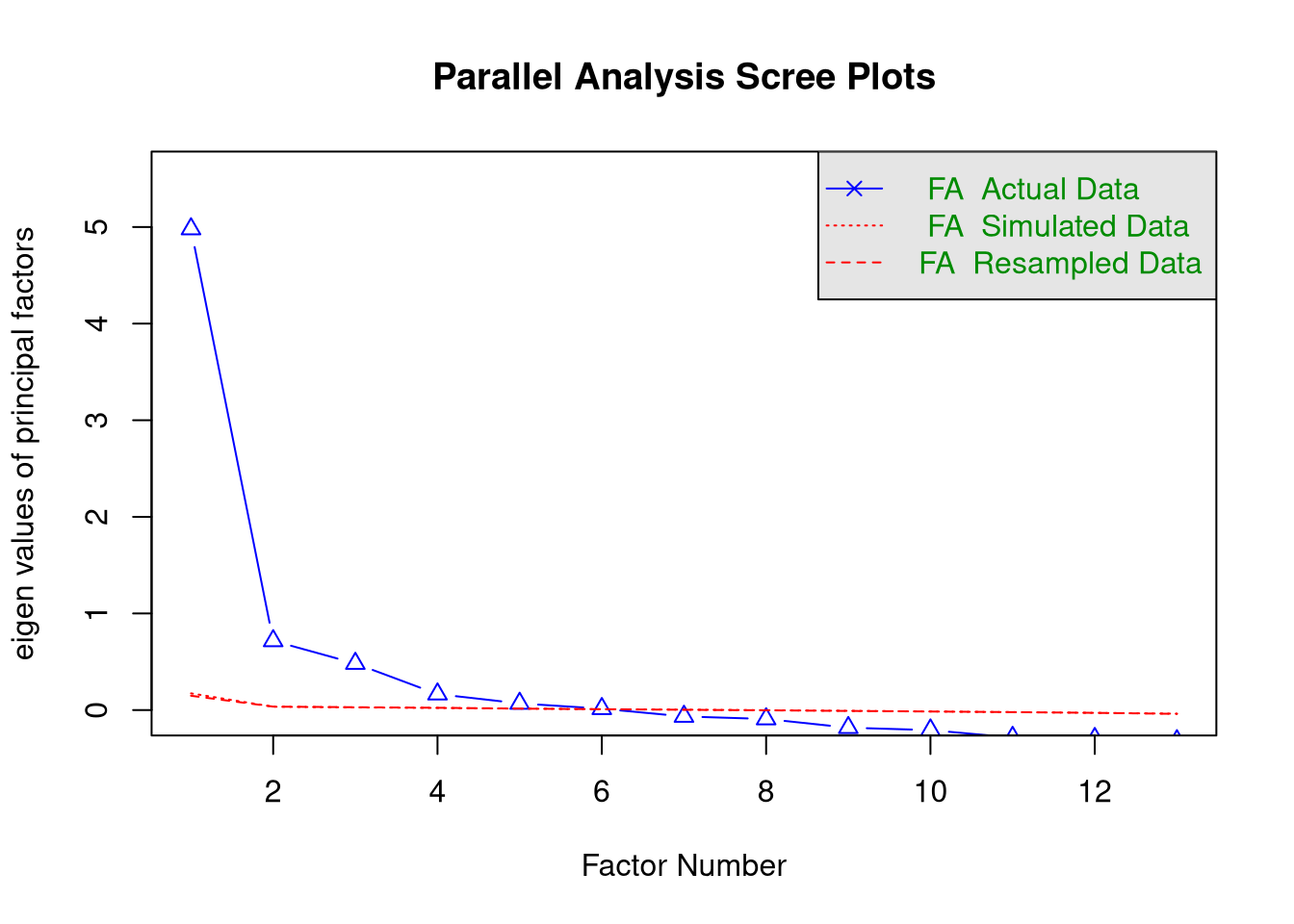
## Parallel analysis suggests that the number of factors = 6 and the number of components = NAClick for explanation
The results of the parallel analysis suggest 6 factors.
If you’ve been paying close attention, you may have noticed that we need to compute the eigenvalues from the original data to run parallel analysis. Hence, we don’t actually need to run a separate EFA to estimate the eigenvalues.
## [1] 4.97995262 0.71644127 0.48201040 0.16517645 0.06885820 0.01422241
## [7] -0.06606777 -0.09225113 -0.18231333 -0.20740917 -0.28415857 -0.29573407
## [13] -0.31877470## [1] 0 0 0 0 0 0 0 0 0 0 0 0 0## Recreate the scree plot from above:
pa_trust %$% data.frame(y = fa.values, x = 1:length(fa.values)) %>%
ggplot(aes(x, y)) +
geom_line() +
xlab("No. of Factors") +
ylab("Eigenvalues")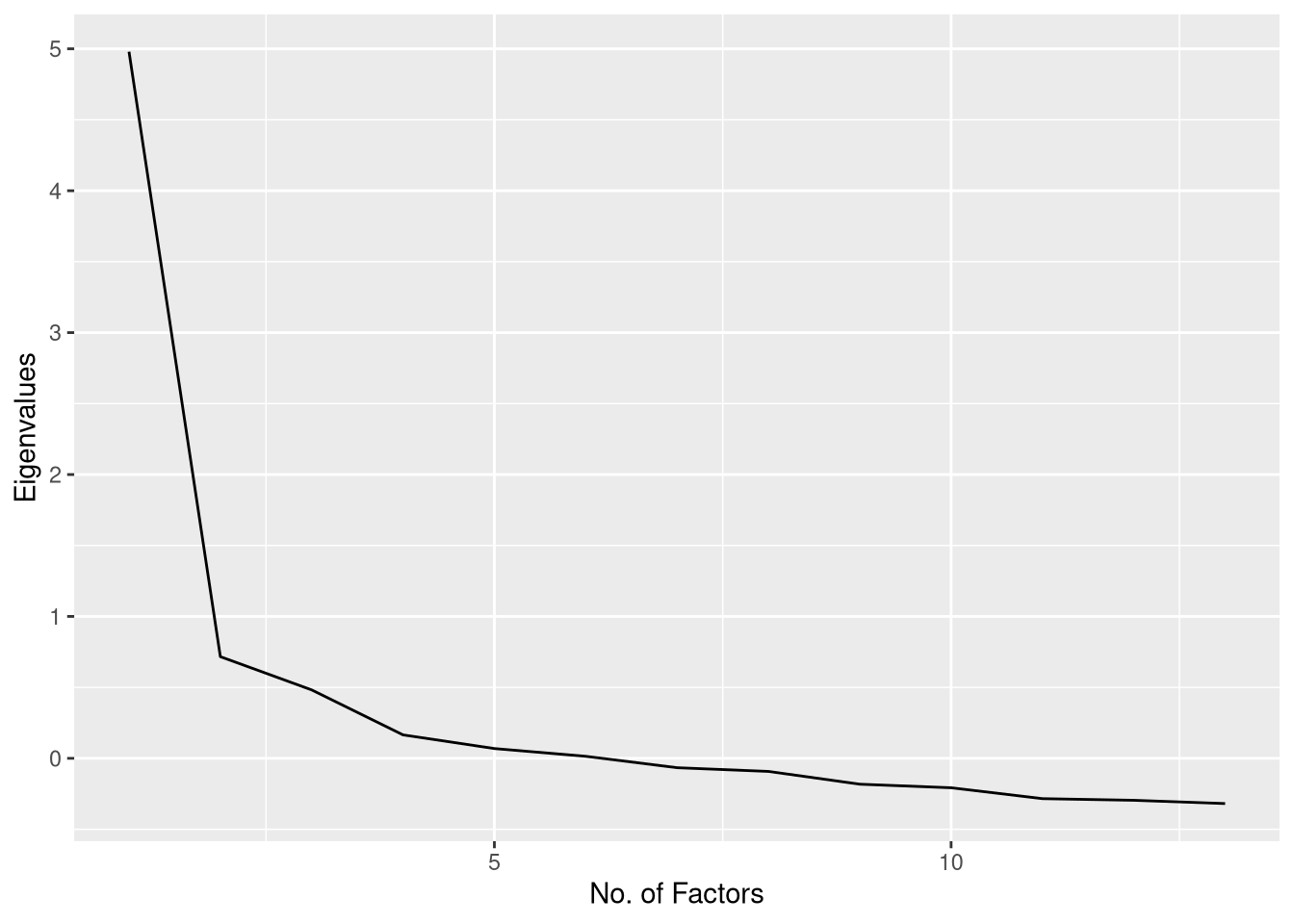
Of course, we also see the same scree plot printed as part of the parallel analysis. So, there’s really no reason to create a separate scree plot, at all, if we’re doing parallel analysis.
4. Conclusion
Click for explanation
The different criteria disagree on how many factors we should extract, but we have narrowed the range.
- Based on the scree plot and parallel analysis, we should consider solutions for 3 to 6 factors.
- We need to examine the factor loadings to see which solution makes the most substantive sense.
4.4.5
Do the same analysis for the attitudes toward immigration items.
Click to show code
This time, we’ll start by running the parallel analysis and get the eigenvalues
and scree plot from psych::fa.parallel().
## Set the seed:
set.seed(235711)
## Run parallel analysis on the 'attitudes' items:
pa_att <- select(ess, imsmetn:rfgbfml) %>% fa.parallel(fa = "fa")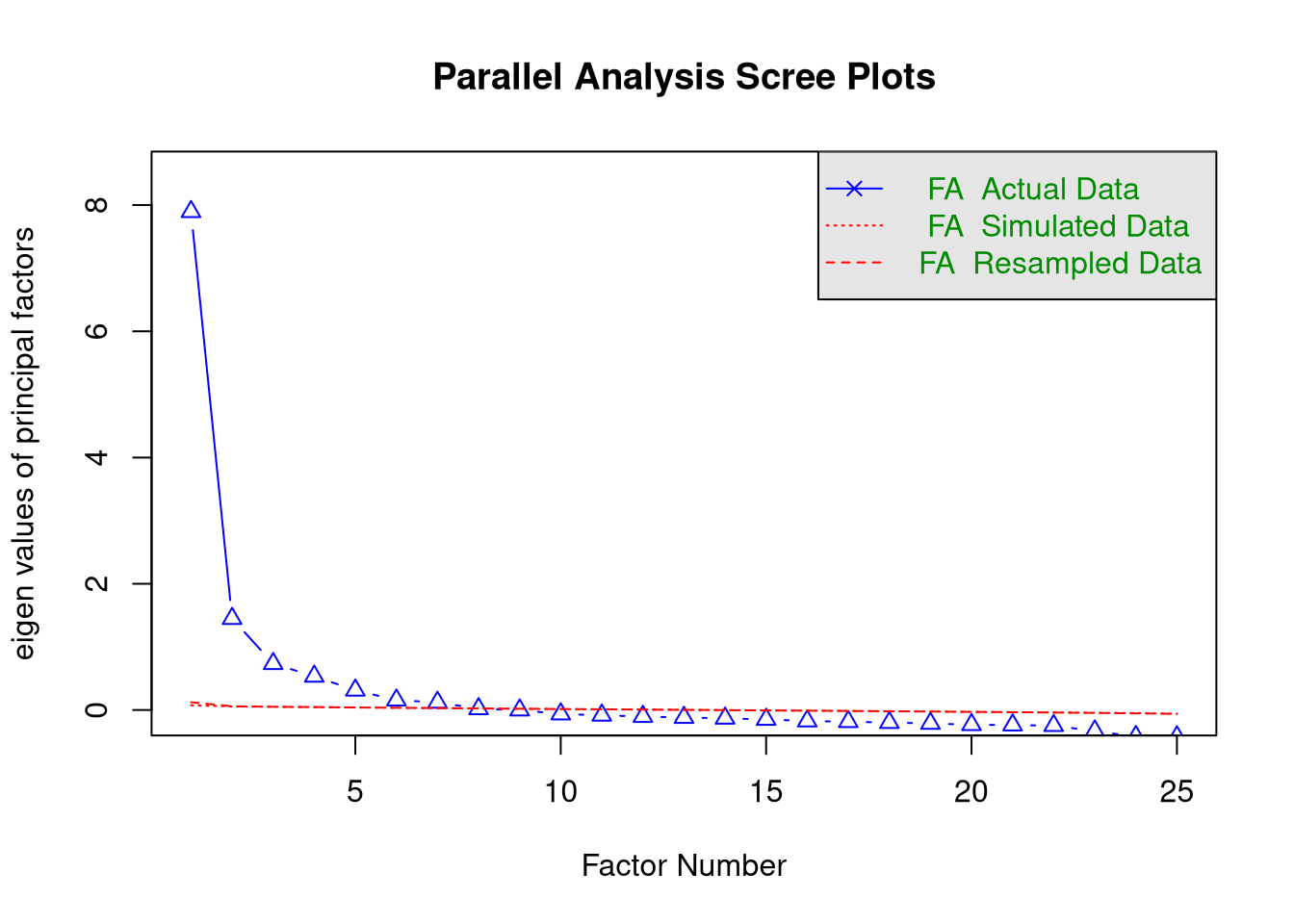
## Parallel analysis suggests that the number of factors = 7 and the number of components = NA## [1] 7.895 1.449 0.734 0.533 0.313 0.156 0.121 0.019 -0.001 -0.064
## [11] -0.083 -0.103 -0.119 -0.131 -0.150 -0.175 -0.185 -0.200 -0.212 -0.233
## [21] -0.239 -0.247 -0.334 -0.422 -0.427Click for explanation
For the attitudes toward immigration analysis, the results are even more ambiguous than they were for the trust items.
- The Kaiser Criterion suggests 2 factors.
- The scree plot is hopelessly ambiguous.
- At least 3 factors?
- No more than 9 factors?
- Parallel analysis suggests 7 factors
Based on the scree plot and parallel analysis, it seems reasonable to consider solutions for 3 to 7 factors.
Again, we need to check the substantive interpretation to choose the most reasonable solution.
To evaluate the substantive interpretability of the different solutions, we need to estimate the full EFA models for each candidate number of factors. We then compare the factor loadings across solutions to see which set of loadings define the most reasonable set of latent variables.
4.4.6
For the trust items, estimate the EFA models for each plausible number of components that you identified above.
- Use the
psych::fa()function to estimate the models.
You will need to specify a few key options.
- The data (including only the variables you want to analyze)
- The number of factors that you want to extract
- The rotation method
- The estimation method
- The method of estimating factor scores
Hint: You can save yourself a lot of typing/copy-pasting (and the attendant
chances of errors) by using a for() loop to iterate through numbers of factors.
Click to show code
## Define an empty list to hold all of our fitted EFA objects:
efa_trust <- list()
## Loop through the interesting numbers of factors and estimate an EFA for each:
for(i in 3:6)
efa_trust[[as.character(i)]] <- ess %>%
select(trstlgl:trstplt) %>%
fa(nfactors = i, # Number of factors = Loop index
rotate = "promax", # Oblique rotation
scores = "Bartlett") # Estimate factor scores with WLS4.4.7
Repeat the above analysis for the attitudes items.
Click to show code
4.4.8
Compare the factor loading matrices from the models estimated from the Trust items, and select the best solution.
Hints:
- The factor loadings are stored in the
loadingsslot of the object returned bypsych::fa(). - Looping can also be useful here.
Click to show code
##
## Loadings:
## MR3 MR2 MR1
## trstlgl 0.839 -0.115
## trstplc 0.763 -0.218
## trstun 0.579 0.161
## trstep 0.554 0.198
## trstprl 0.444 0.342
## stfhlth 0.656 -0.125
## stfedu 0.695 -0.157
## stfeco -0.102 0.704 0.146
## stfgov 0.593 0.226
## stfdem 0.183 0.476 0.150
## pltinvt 0.813
## pltcare 0.808
## trstplt 0.330 0.526
##
## MR3 MR2 MR1
## SS loadings 2.299 2.016 1.970
## Proportion Var 0.177 0.155 0.152
## Cumulative Var 0.177 0.332 0.483
##
## Loadings:
## MR2 MR1 MR4 MR3
## trstlgl 0.797
## trstplc 0.725
## trstun 0.656 0.113
## trstep 1.003 -0.175
## trstprl 0.121 0.455 0.200 0.112
## stfhlth 0.663 -0.106
## stfedu 0.704 -0.110 0.100
## stfeco 0.729
## stfgov 0.631 0.175 -0.149
## stfdem 0.501 0.107 0.115
## pltinvt 0.855
## pltcare -0.103 0.863
## trstplt 0.479 0.340
##
## MR2 MR1 MR4 MR3
## SS loadings 2.161 1.952 1.722 1.239
## Proportion Var 0.166 0.150 0.132 0.095
## Cumulative Var 0.166 0.316 0.449 0.544
##
## Loadings:
## MR1 MR4 MR5 MR3 MR2
## trstlgl 0.935
## trstplc 0.810
## trstun 0.505 0.168
## trstep -0.138 1.128 -0.108 -0.154
## trstprl 0.359 0.250 0.140 0.201 -0.104
## stfhlth 0.557
## stfedu 0.752
## stfeco 0.710 -0.118 0.172
## stfgov 0.973 -0.132
## stfdem 0.556 0.153
## pltinvt 0.882
## pltcare 0.855
## trstplt 0.288 0.308 0.313
##
## MR1 MR4 MR5 MR3 MR2
## SS loadings 2.019 1.716 1.655 1.674 0.936
## Proportion Var 0.155 0.132 0.127 0.129 0.072
## Cumulative Var 0.155 0.287 0.415 0.543 0.615
##
## Loadings:
## MR5 MR1 MR4 MR3 MR2 MR6
## trstlgl 0.980
## trstplc 0.655
## trstun 0.911
## trstep -0.116 0.739 0.163
## trstprl 0.197 0.577 0.138
## stfhlth 0.614
## stfedu 0.771
## stfeco 0.689 -0.123 0.144
## stfgov 0.891
## stfdem 0.513 0.144
## pltinvt 0.816
## pltcare 0.778
## trstplt 0.706 0.193
##
## MR5 MR1 MR4 MR3 MR2 MR6
## SS loadings 1.606 1.417 1.442 1.327 1.014 0.879
## Proportion Var 0.124 0.109 0.111 0.102 0.078 0.068
## Cumulative Var 0.124 0.233 0.343 0.446 0.524 0.591Click for explanation
Note: Any factor loadings with magnitude lower than 0.1 are suppressed in above output.
The factor loadings matrix indicates how strongly each latent factor (columns) associates with the observed items (rows). We can interpret these factor loadings in the same way that we would interpret regression coefficients (indeed, a factor analytic model can be viewed as a multivariate regression model wherein the latent factors are the predictors and the observed items are the outcomes).
- A higher factor loading indicates a stronger association between the item and
factor linked by that loading.
- Items with high factor loadings are “good” indicators of the respective factors.
- Items with only very low loadings do not provide much information about any factor.
- You may want to exclude such items from your analysis.
- Note that the size of the factor loadings depends on the number of factors. So, you should only consider excluding an observed item after you have chosen the number of latent factors.
When we print the loading matrix, we see additional information printed below the factor loadings.
- Proportion Var: What proportion of the items’ variance is explained by each of the factors.
- Cumulative Var: How much variance the factors explain, in total.
- If you estimated as many factors as items, then the Cumulative Var for
the final factor would be
1.00(i.e., 100%).
- If you estimated as many factors as items, then the Cumulative Var for
the final factor would be
4.4.9
Compare the factor loading matrices from the models estimated from the Attitudes items, and select the best solution.
Click to show code
##
## Loadings:
## MR1 MR2 MR3
## imsmetn 0.802
## imdfetn 0.754 0.106
## eimrcnt 0.843
## eimpcnt 0.814
## imrcntr 0.857
## impcntr 0.769
## qfimchr 0.235 0.858
## qfimwht 0.132 0.719
## imwgdwn 0.293 -0.181
## imhecop 0.371 -0.162
## imtcjob 0.619
## imbleco 0.702
## imbgeco 0.687
## imueclt 0.561 -0.207
## imwbcnt 0.732
## imwbcrm 0.637
## imrsprc -0.494 -0.125
## pplstrd 0.249 -0.413
## vrtrlg -0.275 0.240
## shrrfg 0.514 -0.111
## rfgawrk -0.386
## gvrfgap -0.601 -0.148
## rfgfrpc 0.432
## rfggvfn -0.489
## rfgbfml -0.545
##
## MR1 MR2 MR3
## SS loadings 4.819 3.950 1.683
## Proportion Var 0.193 0.158 0.067
## Cumulative Var 0.193 0.351 0.418
##
## Loadings:
## MR2 MR4 MR1 MR3
## imsmetn 0.788
## imdfetn 0.731 0.153 0.110
## eimrcnt 0.855 -0.143
## eimpcnt 0.790 0.165
## imrcntr 0.860
## impcntr 0.743 0.182
## qfimchr -0.122 0.853
## qfimwht 0.723
## imwgdwn 0.638 0.264
## imhecop 0.680 0.217
## imtcjob 0.633 0.136
## imbleco 0.563 -0.212 0.153
## imbgeco 0.604 -0.168
## imueclt 0.392 -0.236 -0.168
## imwbcnt 0.526 -0.282
## imwbcrm 0.397 -0.292
## imrsprc 0.616
## pplstrd 0.231 -0.378
## vrtrlg 0.279 0.264
## shrrfg 0.299 -0.271
## rfgawrk 0.452
## gvrfgap 0.123 0.774
## rfgfrpc 0.193 -0.281
## rfggvfn 0.467
## rfgbfml 0.619
##
## MR2 MR4 MR1 MR3
## SS loadings 3.828 2.778 2.570 1.602
## Proportion Var 0.153 0.111 0.103 0.064
## Cumulative Var 0.153 0.264 0.367 0.431
##
## Loadings:
## MR2 MR1 MR5 MR3 MR4
## imsmetn 0.792
## imdfetn 0.728 0.169 0.113
## eimrcnt 0.910 -0.150 -0.237
## eimpcnt 0.779 0.126 0.213
## imrcntr 0.910 -0.128 -0.187
## impcntr 0.731 0.131 0.236
## qfimchr 0.109 -0.156 0.882
## qfimwht 0.139 0.736
## imwgdwn 0.740
## imhecop 0.700
## imtcjob 0.543 0.124 0.182
## imbleco 0.682 0.135
## imbgeco 0.799
## imueclt 0.572 -0.202
## imwbcnt 0.712
## imwbcrm 0.545 -0.124
## imrsprc 0.620
## pplstrd 0.207 -0.396
## vrtrlg -0.198 0.151 0.285 0.116
## shrrfg 0.208 -0.263 0.139
## rfgawrk 0.457
## gvrfgap 0.783
## rfgfrpc -0.338 0.156
## rfggvfn 0.477
## rfgbfml -0.125 0.538
##
## MR2 MR1 MR5 MR3 MR4
## SS loadings 3.970 2.790 2.215 1.693 1.166
## Proportion Var 0.159 0.112 0.089 0.068 0.047
## Cumulative Var 0.159 0.270 0.359 0.427 0.473
##
## Loadings:
## MR2 MR1 MR6 MR3 MR5 MR4
## imsmetn 0.705 0.166
## imdfetn 0.833
## eimrcnt 0.249 0.859
## eimpcnt 0.946
## imrcntr 0.456 0.517
## impcntr 0.951
## qfimchr 0.134 -0.122 0.875
## qfimwht 0.151 0.725
## imwgdwn 0.748
## imhecop 0.678
## imtcjob 0.566 0.123 0.175
## imbleco 0.753 0.144
## imbgeco 0.822
## imueclt 0.580 -0.201
## imwbcnt 0.751
## imwbcrm 0.597
## imrsprc 0.146 0.527
## pplstrd 0.204 -0.392
## vrtrlg -0.204 0.143 0.281 0.115
## shrrfg 0.198 -0.275 0.141
## rfgawrk 0.517
## gvrfgap 0.784
## rfgfrpc -0.294 0.144
## rfggvfn 0.512
## rfgbfml 0.596
##
## MR2 MR1 MR6 MR3 MR5 MR4
## SS loadings 3.304 3.013 1.994 1.649 1.065 1.133
## Proportion Var 0.132 0.121 0.080 0.066 0.043 0.045
## Cumulative Var 0.132 0.253 0.332 0.398 0.441 0.486
##
## Loadings:
## MR2 MR1 MR6 MR3 MR5 MR7 MR4
## imsmetn 0.700 0.162
## imdfetn 0.821
## eimrcnt 0.245 0.879
## eimpcnt 0.935
## imrcntr 0.452 0.523
## impcntr 0.938
## qfimchr 0.751
## qfimwht 0.720
## imwgdwn 0.700
## imhecop 0.172 0.624
## imtcjob 0.574 -0.120 0.174
## imbleco 0.679 0.108
## imbgeco 0.832 -0.145
## imueclt 0.531 -0.191
## imwbcnt 0.649 0.138
## imwbcrm 0.464 0.131 0.290
## imrsprc 0.146 0.440 -0.100
## pplstrd -0.274 0.392
## vrtrlg -0.121 0.190 -0.297 0.115
## shrrfg -0.124 0.437 0.131
## rfgawrk 0.538
## gvrfgap 0.616 -0.237
## rfgfrpc -0.131 0.437 0.135
## rfggvfn 0.504
## rfgbfml 0.526
##
## MR2 MR1 MR6 MR3 MR5 MR7 MR4
## SS loadings 3.224 2.467 1.456 1.305 1.105 0.901 0.984
## Proportion Var 0.129 0.099 0.058 0.052 0.044 0.036 0.039
## Cumulative Var 0.129 0.228 0.286 0.338 0.382 0.418 0.458It is very possible that you selected a different numbers of factors than Kestilä (2006). We need to keep these exercises consistent, though. So, the remaining questions will all assume you have extract three factors from the Trust items and five factors from the Attitudes items, to parallel the Kestilä (2006) results.
## Select the three-factor solution for 'trust':
efa_trust <- efa_trust[["3"]]
## Select the five-factor solution for 'attitudes':
efa_att <- efa_att[["5"]]4.4.10
Give the factor scores meaningful names, and add the scores to the ess dataset
as new columns.
Hint: If you’re not sure of what do to, check 4.3.11.
Click to show code
Kestilä (2006) used the component scores to descriptively evaluate country-level differences in Attitudes toward Immigration and Political Trust. So, now it’s time to replicate those analyses.
4.4.11
Repeat the Kestilä (2006) between-country comparison using the factor scores you created in 4.4.10 and an appropriate statistical test.
Click to show code
Here, we’ll only demonstrate a possible approach to analyzing one of the Trust dimensions. We can use a linear model to test whether the countries differ in average levels of Trust in Institutions (as quantified by the relevant factor score).
## Estimate the model:
out <- lm(trust_inst ~ country, data = ess)
## View the regression-style summary:
summary(out)##
## Call:
## lm(formula = trust_inst ~ country, data = ess)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.2295 -0.6226 0.1171 0.7194 3.3061
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.09028 0.02445 -3.692 0.000224 ***
## countryBelgium -0.28923 0.03642 -7.942 2.12e-15 ***
## countryGermany -0.05966 0.03211 -1.858 0.063205 .
## countryDenmark 0.75509 0.03882 19.452 < 2e-16 ***
## countryFinland 0.59235 0.03439 17.224 < 2e-16 ***
## countryItaly 0.10991 0.04071 2.700 0.006939 **
## countryNetherlands -0.05357 0.03379 -1.585 0.112893
## countryNorway 0.36922 0.03493 10.570 < 2e-16 ***
## countrySweden 0.28560 0.03613 7.904 2.89e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.029 on 14769 degrees of freedom
## (4912 observations deleted due to missingness)
## Multiple R-squared: 0.082, Adjusted R-squared: 0.0815
## F-statistic: 164.9 on 8 and 14769 DF, p-value: < 2.2e-16## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = .)
##
## $country
## diff lwr upr p adj
## Belgium-Austria -0.289225482 -0.40219224 -0.17625873 0.0000000
## Germany-Austria -0.059655996 -0.15926604 0.03995405 0.6429963
## Denmark-Austria 0.755089552 0.63466911 0.87551000 0.0000000
## Finland-Austria 0.592348290 0.48565882 0.69903776 0.0000000
## Italy-Austria 0.109910185 -0.01636587 0.23618624 0.1476635
## Netherlands-Austria -0.053567808 -0.15838407 0.05124846 0.8131104
## Norway-Austria 0.369224250 0.26085692 0.47759158 0.0000000
## Sweden-Austria 0.285601197 0.17350905 0.39769334 0.0000000
## Germany-Belgium 0.229569486 0.12386351 0.33527546 0.0000000
## Denmark-Belgium 1.044315033 0.91880537 1.16982470 0.0000000
## Finland-Belgium 0.881573772 0.76917165 0.99397589 0.0000000
## Italy-Belgium 0.399135667 0.26799745 0.53027389 0.0000000
## Netherlands-Belgium 0.235657673 0.12503199 0.34628336 0.0000000
## Norway-Belgium 0.658449732 0.54445381 0.77244566 0.0000000
## Sweden-Belgium 0.574826679 0.45728417 0.69236918 0.0000000
## Denmark-Germany 0.814745547 0.70110863 0.92838247 0.0000000
## Finland-Germany 0.652004286 0.55303505 0.75097352 0.0000000
## Italy-Germany 0.169566181 0.04974170 0.28939066 0.0003895
## Netherlands-Germany 0.006088188 -0.09085878 0.10303516 0.9999999
## Norway-Germany 0.428880246 0.32810453 0.52965596 0.0000000
## Sweden-Germany 0.345257193 0.24048642 0.45002796 0.0000000
## Finland-Denmark -0.162741262 -0.28263218 -0.04285034 0.0008579
## Italy-Denmark -0.645179366 -0.78279052 -0.50756821 0.0000000
## Netherlands-Denmark -0.808657360 -0.92688442 -0.69043030 0.0000000
## Norway-Denmark -0.385865301 -0.50725174 -0.26447886 0.0000000
## Sweden-Denmark -0.469488354 -0.59421139 -0.34476531 0.0000000
## Italy-Finland -0.482438105 -0.60820928 -0.35666693 0.0000000
## Netherlands-Finland -0.645916098 -0.75012357 -0.54170862 0.0000000
## Norway-Finland -0.223124040 -0.33090264 -0.11534544 0.0000000
## Sweden-Finland -0.306747093 -0.41827017 -0.19522402 0.0000000
## Netherlands-Italy -0.163477993 -0.28766412 -0.03929186 0.0014719
## Norway-Italy 0.259314065 0.13211649 0.38651164 0.0000000
## Sweden-Italy 0.175691012 0.04530545 0.30607657 0.0009794
## Norway-Netherlands 0.422792059 0.31686740 0.52871671 0.0000000
## Sweden-Netherlands 0.339169005 0.22943659 0.44890142 0.0000000
## Sweden-Norway -0.083623053 -0.19675232 0.02950622 0.3462227Click for explanation
According to the omnibus F-test, average levels of Trust in Institutions significantly differ between countries, but this test cannot tell us between which countries the differences lie.
Similarly, the t statistics associated with each dummy code in the regression-style summary only tell us if that country differs significantly from the reference country (i.e., Austria), but we cannot see, for example, if there is a significant difference in average trust levels between Belgium and the Netherlands.
One way to test for differences between the individual countries would be a post hoc test of all pairwise comparisons. Since we’ll be doing 45 tests, we need to apply a correction for repeated testing.
Above, we use the
TukeyHSD()function to conduct all pairwise comparisons while applying Tukey’s HSD correction.The
TukeyHSD()function only accepts models estimated with theaov()function, so we first pass our fitted lm object throughaov().
The second part of the Kestilä (2006) analysis was to evaluate how socio-demographic characteristics affected attitudes towards immigrants and trust in politics among the Finnish electorate. Before we can replicate this part of the analysis, we need to subset the data to only the Finnish cases.
4.4.12
Create a new data frame that contains only the Finnish cases from ess.
Hint: You can use logical indexing based on the country variable.
We still have one more step before we can estimate any models. We must prepare our variables for analysis.
- Our dependent variables will be the factor scores generated above. So, we do not need to apply any further processing.
- We have not yet used any of the independent variables, though. So, we should inspect those variables to see if they require any processing.
In our processed ess data, the relevant variables have the following names:
sexyrbrneduyrspolintrlrscale
4.4.13
Inspect the independent variables listed above.
Click to show code
Click for explanation
It looks like we still need some recoding.
4.4.14
Apply any necessary recoding/transformations.
1. Age
Click to show code
Click for explanation
The data contain the participants’ years of birth instead of their age, but
Kestilä analyzed age. Fortunately, we know that the data were collected in
2002, so we can simply subtract each participant’s value of yrbrn from the
2002 to compute their age.
2. Political Interest
Click to show code
First, we’ll transform polintr.
## Recode the four factor levels into two factor levels:
ess_finland <-
mutate(ess_finland,
polintr_bin = recode_factor(polintr,
"Not at all interested" = "Low Interest",
"Hardly interested" = "Low Interest",
"Quite interested" = "High Interest",
"Very interested" = "High Interest")
)
## Check the conversion:
with(ess_finland, table(old = polintr, new = polintr_bin, useNA = "always"))## new
## old Low Interest High Interest <NA>
## Very interested 0 144 0
## Quite interested 0 785 0
## Hardly interested 842 0 0
## Not at all interested 228 0 0
## <NA> 0 0 1Click for explanation
Kestilä (2006) dichotomized polintr by combining the lowest two and highest
two categories. So, we don’t actually want to convert the polint variable
into a numeric, Likert-type variable. We want polint to be a binary factor.
The recode_factor() function from dplyr() will automatically convert our
result into a factor.
As with the ess_round1.rds data, we will be coming back to this Finnish
subsample data in future practical exercises. So, we should save our work by
writing the processed dataset to disk.
4.4.15
Use the saveRDS() function to save the processed Finnish subsample data.
Now, we’re finally ready to replicate the regression analysis from Kestilä (2006). Creating a single aggregate score by summing the individual component scores is a pretty silly thing to do, though. So, we won’t reproduce that aspect of the analysis.
4.4.16
Run a series of multiple linear regression analyses with the factor scores you created in 4.4.10 as the dependent variables and the same predictors used by Kestilä (2006).
- Do your results agree with those reported by Kestilä (2006)?
Click to show code
## Predicting 'Trust in Institutions':
out_trust_inst <- lm(trust_inst ~ sex + age + eduyrs + polintr_bin + lrscale,
data = ess_finland)
summary(out_trust_inst)##
## Call:
## lm(formula = trust_inst ~ sex + age + eduyrs + polintr_bin +
## lrscale, data = ess_finland)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.9499 -0.5102 0.1337 0.6638 2.5919
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.057518 0.124294 -0.463 0.643595
## sexFemale 0.004091 0.045170 0.091 0.927849
## age -0.003071 0.001380 -2.225 0.026219 *
## eduyrs 0.023223 0.006388 3.635 0.000286 ***
## polintr_binHigh Interest 0.166860 0.046448 3.592 0.000337 ***
## lrscale 0.058951 0.011232 5.249 1.72e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.9321 on 1734 degrees of freedom
## (260 observations deleted due to missingness)
## Multiple R-squared: 0.04155, Adjusted R-squared: 0.03879
## F-statistic: 15.03 on 5 and 1734 DF, p-value: 1.78e-14## Predicting 'Trust in Politicians':
out_trust_pol <- lm(trust_pol ~ sex + age + eduyrs + polintr_bin + lrscale,
data = ess_finland)
summary(out_trust_pol)##
## Call:
## lm(formula = trust_pol ~ sex + age + eduyrs + polintr_bin + lrscale,
## data = ess_finland)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.03673 -0.67306 0.05346 0.69666 2.38771
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.165989 0.126840 -1.309 0.19083
## sexFemale 0.015572 0.046095 0.338 0.73554
## age -0.009112 0.001409 -6.469 1.28e-10 ***
## eduyrs 0.018476 0.006519 2.834 0.00465 **
## polintr_binHigh Interest 0.463763 0.047399 9.784 < 2e-16 ***
## lrscale 0.054932 0.011462 4.793 1.79e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.9512 on 1734 degrees of freedom
## (260 observations deleted due to missingness)
## Multiple R-squared: 0.09806, Adjusted R-squared: 0.09546
## F-statistic: 37.71 on 5 and 1734 DF, p-value: < 2.2e-16## Predicting 'Attitudes toward Refugees':
out_refugees <- lm(refugees ~ sex + age + eduyrs + polintr_bin + lrscale,
data = ess_finland)
summary(out_refugees)##
## Call:
## lm(formula = refugees ~ sex + age + eduyrs + polintr_bin + lrscale,
## data = ess_finland)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.9118 -0.6860 -0.0594 0.6904 4.1044
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.690e-01 1.438e-01 -1.175 0.240080
## sexFemale -4.828e-01 5.181e-02 -9.318 < 2e-16 ***
## age 2.903e-05 1.604e-03 0.018 0.985561
## eduyrs -2.537e-02 7.459e-03 -3.401 0.000688 ***
## polintr_binHigh Interest -2.131e-01 5.345e-02 -3.986 6.99e-05 ***
## lrscale 9.359e-02 1.296e-02 7.223 7.65e-13 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.06 on 1699 degrees of freedom
## (295 observations deleted due to missingness)
## Multiple R-squared: 0.09535, Adjusted R-squared: 0.09269
## F-statistic: 35.81 on 5 and 1699 DF, p-value: < 2.2e-16That does it for our replication of the Kesilä (2006) analyses, but we still have one more topic to consider in this practical. One of the most common applications of EFA is scale development. Given a pool of items without a known factor structure, we try to estimate the underlying latent factors that define the (sub)scales represented by our items.
In such applications, we use the factor loading matrix for our optimal solution to make “bright-line” assignments of items to putative factors according to the simple structure represented by the estimated factor loading matrix. In other words, we disregard small factor loadings and assign observed items to only the single latent factor upon which they load most strongly. We then hypothesize that those items are true indicators of that latent factor.
We can use confirmatory factor analysis (which you will learn about next week) to test rigorously this hypothesis, but we can already get started by estimating the internal consistency (a type of reliability) of the hypothesized subscales.
4.4.17
Estimate the internal consistency of the three Trust subscales and five Attitudes subscales implied by your EFA solutions from above.
- Use Cronbach’s Alpha to quantify internal consistency.
- Use the
alpha()function from the psych package to conduct the analysis. - Run your analysis on the full
essdataset, not the Finnish subset.
Are the subscales implied by your EFA reliable, in the sense of good internal consistency?
- Note that \(\alpha > 0.7\) is generally considered acceptable, and \(\alpha > 0.8\) is usually considered good.
Click to show code
## Run the reliability analysis on the subscale data:
(
out <- select(ess, starts_with("stf")) %>%
psych::alpha()
)##
## Reliability analysis
## Call: psych::alpha(x = .)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.79 0.8 0.77 0.44 3.9 0.0023 5.4 1.7 0.42
##
## 95% confidence boundaries
## lower alpha upper
## Feldt 0.79 0.79 0.8
## Duhachek 0.79 0.79 0.8
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## stfhlth 0.78 0.78 0.74 0.47 3.6 0.0026 0.0063 0.47
## stfedu 0.76 0.76 0.72 0.45 3.2 0.0028 0.0109 0.44
## stfeco 0.74 0.74 0.70 0.42 2.8 0.0031 0.0069 0.39
## stfgov 0.74 0.75 0.70 0.42 2.9 0.0030 0.0035 0.42
## stfdem 0.75 0.75 0.71 0.43 3.0 0.0029 0.0074 0.41
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## stfhlth 19481 0.69 0.69 0.56 0.50 5.8 2.3
## stfedu 18844 0.73 0.73 0.62 0.55 5.9 2.3
## stfeco 19211 0.78 0.78 0.71 0.63 5.0 2.4
## stfgov 19106 0.77 0.76 0.69 0.61 4.5 2.3
## stfdem 19106 0.75 0.75 0.67 0.59 5.7 2.3Click for explanation
Here, we estimate the reliability of the Satisfaction subscale from the Trust analysis. According to our EFA, the Satisfaction subscale should be indicated by the following five variables:
stfecostfgovstfdemstfedustfhlth
We select these variables using the tidy-select function starts_with() to
extract all variables beginning with the three characters “stf”. To estimate
the internal consistency of this subscale, we simply provide a data frame
containing only the subscale data to the alpha() function.
The raw_alpha value is the estimate of Cronbach’s Alpha. In this case
\(\alpha = 0.794\), so the subscale is pretty reliable.
The table labeled “Reliability if an item is dropped” shows what Cronbach’s
Alpha would be if each item were excluded from the scale. If this value is
notably higher than the raw_alpha value, it could indicate a bad item.
Note that reliability is only one aspect of scale quality, though. So, you shouldn’t throw out items just because they perform poorly in reliability analysis.
End of In-Class Exercises